Alice and Bob
If you work in the IT field, then you might have ended up reading the stories of ‘Alice and Bob’.
Alice and Bob are fictional characters commonly used as placeholders. It is a convenient way to tell a story when Alice and Bob are there, instead of using person X and person Z or ‘Cthulhu’ and ‘Godzilla’.
 How I imagine Alice: Sitting on the left. The guy on the right might be Bob.
How I imagine Alice: Sitting on the left. The guy on the right might be Bob.
Fabio and Bob
Now, it turns out that I have a colleague called Bob. Bob is a developer, very skilled and also accurate in his job.
I like Bob.
Bob is working on porting a project to Kubernetes.
That project uses Kafka as data store and was originally written long time ago by some other colleagues.
Also, it turns out that my name is Fabio and not Alice. Therefore today I’m going to tell you the story of… Fabio and Bob!
The Idea
One cold winter morning Fabio is walking his dog and thinking about the recent work he did to setup (yet another) Kafka on the k8s dev environment.
Unlike the previous Kafka project he rolled out, he did not give all instructions and directions to his developers colleagues.
Fabio: After all, it is not a brand new project but we are porting something that already existed.
Inner Fabio: yes, but… now Kafka runs in replica and not standalone. And also the previous time developers ‘just made it running’.
Then Fabio goes back home, and calls Bob…
Fabio: Hey Bob, did you review the Kafka producer settings?
Bob: No, I did not but it might be a good idea.
Not long after we realized that producer was not guaranteeing ‘Atomicity’. Therefore commits might get lost.
After Bob fixed that, we then started digging more into the rabbit hole and we ended up benchmarking around data compression…
Compress or not Compress. That is the question
Kafka compression is about (ehm..) compressing data instead of sending data as they are. Some data responds better to compression than other and some algorithm performs better than others.
Possible compression options in the producer are: none, gzip, snappy, lz4 and zstd.
Compression can be handled by the producer. That is: producer compresses data before sending to Kafka. Consumer reads data and decompresses it. Kafka will store data in a compressed form.
That saves: bandwidth, disk space, RAM at the price of some CPU used to compress and decompress.
The outcome of our research might be different from your case. We use FHIR data, and if you want to also use compression, I invite you to perform the same tests on your data.
Need help? Just get in touch (how? see bottom of the article)!
Devops, here we go again
As often happens to me, this has been a real devops effort.
Fabio: hey Bob, can you load some data on Kafka for me?
Bob: Yes, which topic do you want me to pick?
F: Pick one relatively fat topic, with thousands of messages. We do the first run using compression=none to check how much data is in there.
B: Nice, I ll give you a sign
In the meanwhile, Fabio takes note of the data size, so it can be compared with the size when the current run finished.
Another thing we are interested in is the time it takes to load data. How to know? Running a Kafka consumer it is possible to show the offset of the messages.
B: I’m ready!
F: Go Bob, go!
data is loaded and we got the following numbers:
size in bytes: 140480986 time in ms: 144963
Now that we had a baseline, we repeated the exercise using different compressions.
This is the result:
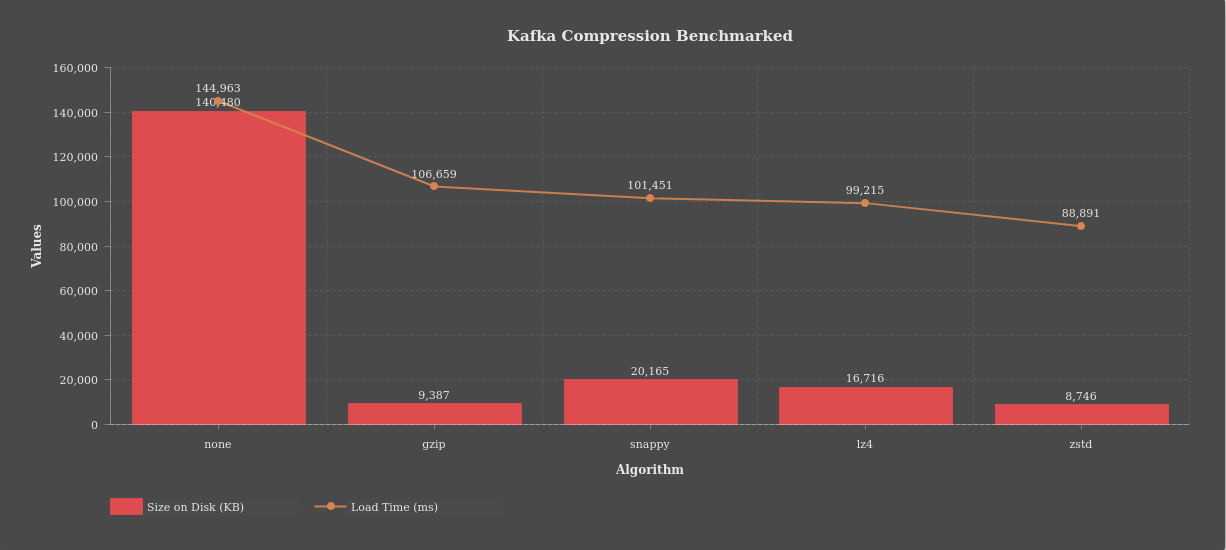
Compressing data makes the difference in terms of disk space used: FHIR data takes 16 times less space and loads almost 2 times faster!
When you have a lot of data, if you compress or not will make a great difference. You are going to save on disk costs and RAM at the expenses of some CPU on the producer and consumer side.
Now, let’s imagine you plan to have a Kafka cluster running 3 brokers, serving 1TB of data hosted on AWS, on General purpose SSD.
Using the AWS calculator, that will cost you 365 US$ per month, per cluster. And.. Hey! Are you using DTAP? then it is 4 clusters! (+ maybe one for Disaster Recovery…).
4 clusters will bring the bill to 365 * 4 = 1464 US$ per month
If you did your home work then probably you want Kafka to use compression. So you do not need 1TB any longer but 1TB / 16 = 64 GB and the cost will be only 23 US$ per cluster!
You just saved 342 dollars per cluster you run, per month! DTAP? then you saved 1368 dollars per month, 16416 dollars per year.
Not bad, eh?
Our tests went further, and we were able to bring the storage requirements even more down, playing with some other Kafka settings… But I will maybe tell you this story another time.
Conclusions
Every technology comes with some home works and Kafka is no exception. The time spent in studying how a technology works is of course time well spent.
If you do not have that time, you can still hire an expert to do the job for you. You might end up spending a few hundred dollars and have an huge return for all the years to come.